





技術コラム
AI ハイパー パラメータの調整
AIの世界では、人間が調整しなくてはいけないパラメータを「ハイパーパラメータ」と言います。
AIは、AI自身がいろいろと考えてくれますが、最終的に人間が調整しなくてはならないパラメータは残り、その調整方法に悩まされます。AIにはまだ、PID制御のような確立された調整方法がありません。
ここでは、AIマイコンボード「DT-EBML63Q2557」の「ハイパーパラメータ」と、その調整方法の攻略をざっくりと述べていきます。どんな場合にでも当てはまるものではないことに注意してください。「ハイパーパラメータ」調整の参考になればと思います。
■隠れ層ノード数 (影響は小さい)
3層ニューラルネットワーク隠れ層のノード数です。
FFTを施したデータや滑らかなデータには少なめ、細かい変化のギザギザしたようなデータには多めに設定します。
20くらいで推論できるなら、それ以上あまり増やしても良くはなりません。
■活性化関数 (影響は大きい)
Linear、Sigmoid、reLU、Tanhがあります。
SigmoidとTanhは、入力データの値にリミッターを掛けるような働きがあります。
reLUは、マイナスの値を0に置き換えます。
入力データの値が0付近であまりにも小さいと、AIがうまく判断できない場合があります。
入力データの値(マイナスがある場合は絶対値)が、10だとか、100くらい、または活性化関数が反応する範囲で変化するように、前処理で調整するのが良いようです。
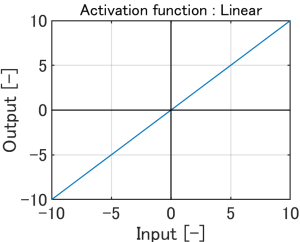 活性化関数は、何も変化を与えません。 |
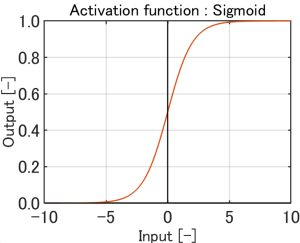 概ね-5.0~5.0の入力が、 0~1.0の範囲になります。 入力が-5.0~5.0の範囲を外れると、 約0と、約1.0で2値化します。 |
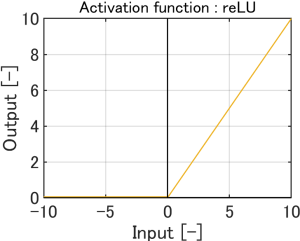 マイナスの入力値は0になります。 |
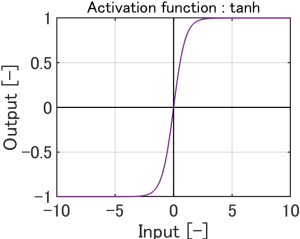 概ね-2.0~2.0の入力が、 -1.0~1.0の範囲になります。 入力が-2.0~2.0の範囲を外れると、 約-1.0と、約1.0で2値化します。 |
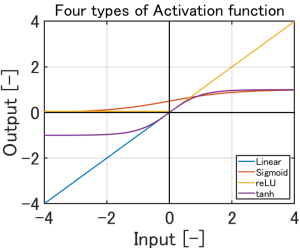 4つの活性化関数を重ねると、 このようになります。 |
■損失関数 (影響は大きい)
正常だと思われるデータと、入力データを比較するときに使われる関数で、つぎのふたつがあります。
MAE (平均絶対誤差) : 正常時の異常度の変動が大きい場合に適しています。
MSE (平均二乗誤差) : 正常時の異常度の変動が小さい場合に適しています。
| MAE(平均絶対誤差) | MSE(平均二乗誤差) |
|---|---|
 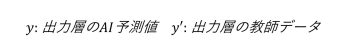
|

|
|
MAE はデータ全体にわたって生じるような外れ値の検知に強いです。 例えば、頻繁にノイズが混入するような場合に有効です。 |
MSE はデータ全体に対して局所的な外れ値に敏感です。 例えば、時系列データの一部の微小変動を重視したいときなどです。 |
■忘却率 (影響は大きい)
学習させているあいだは、繰り返し何回も学習が行なわれます。
忘却率の値が1未満で小さいほど、毎回の学習結果が反映される(追学習の)比率が大きくなります。
追学習をさせすぎる(忘却率が0に近づくほど)と、過学習や、発散しやすくなります。
推論時には影響しません。
弊社のサンプルソフトでは、いったん推論させたあと、重みデータをクリアせずに再び学習させた場合も、追学習ができます。
過学習:
学習終盤に収束していったときの異常度に対して、推論時の正常データの異常度が大きい場合、過学習が疑われます。
過学習になると、学習したのと同じデータに対しては異常度が小さくなりますが、学習したのと少しでも違う正常データに対して、異常度が大きくなる傾向があります。
現実のデータには正常データであっても、センサノイズ、温度などの環境変動、個体差、経年変化など、微小な違いが必ず生じます。
過学習したモデルは、この自然なばらつきを「正常の範囲」と認識できず、わずかな違いを “異常” と判断してしまうことがあります。
■シード値 (影響は小さい)
重みを算出する際に使われる乱数の種(シード)となる値です。
10~100くらいの範囲で10回くらい値を変えて、良い推論結果が出るものを選びます。
推論結果に影響を与える場合と、そうではない場合があります。
活性化関数 reLU では、シード値による影響は、他の活性化関数に比べて顕著です。
